
Co je sentiment?
Sentiment je emocionální tón nebo postoj, který je vyjádřen v textu. Tento sentiment může být pozitivní, negativní, neutrální. Nebo takto:

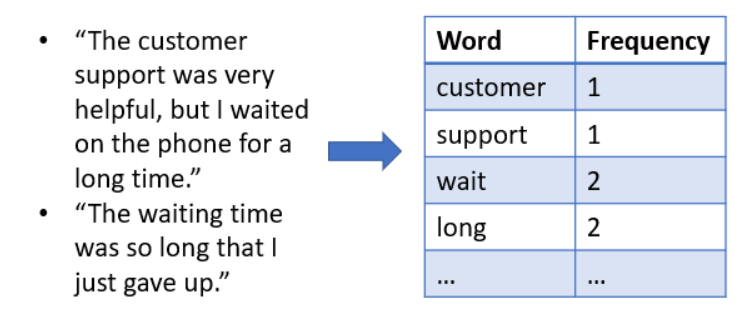
Krok 1) Získání dat:
Nashromážděná textová data bude poté třeba očistit od částí, které nevyjadřují žádný význam. Poté je třeba text kategorizovat do slov nebo skupin slov, které lze označit jako pozitivní nebo negativní.
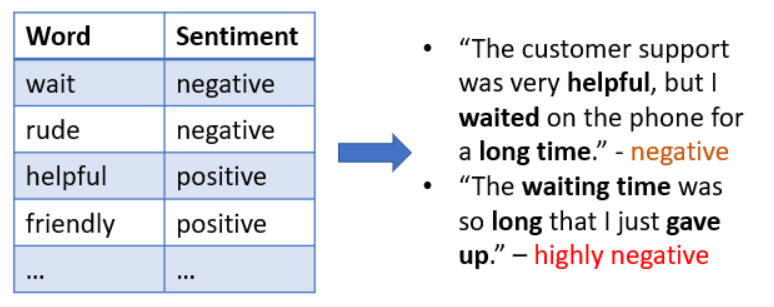
Krok 2) Vyberte vhodný model pro analýzu sentimentu
- Model založený na pravidlech je nejjednodušším přístupem pro analýzu sentimentu, což je označování dat. Označení dat klasifikuje slova v extrahovaném textu jako negativní nebo pozitivní. Například recenze obsahující slova „dobré, skvělé, úžasné“ by byly označeny jako pozitivní recenze, zatímco recenze obsahující „špatné, hrozné, zbytečné“ by byly označeny jako negativní slova. Tento heuristický nápad může velmi rychle poskytnout nápad na vysoké úrovni, ale chyběly by komentáře, které obsahují méně frekventovaná slova nebo komplikované významy, které obsahují negativní i pozitivní slova.
- Model strojového učení vyžaduje trochu manuálního úsilí při vytváření modelu, ale časem by poskytl přesnější a automatizovanější výsledky. Jakmile budete mít k analýze velké množství textových dat, rozdělili byste určitou jejich část jako testovací sadu a ručně označili každý komentář jako pozitivní nebo negativní. Později by model strojového učení tyto vstupy zpracoval a porovnal nové komentáře se stávajícími a kategorizoval je jako pozitivní nebo negativní slova na základě podobnosti. Jednou z výhod tohoto modelu je, že trénovací data by pokrývala více příkladů méně frekventovaných slov nebo obrazných frází, model by byl schopen rozpoznat tyto vzorce v nových datech a přesně klasifikovat složitější komentáře.
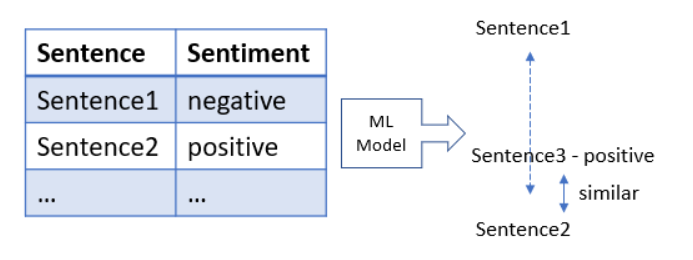
Krok 3) Analyzujte a vyhodnoťte
Jak modely založené na pravidlech, tak modely strojového učení lze časem vylepšit. Například slovník záporných a pozitivních slov lze aktualizovat jako živý zdroj odkazů, aby byla nová data přesněji klasifikována. Podobně existuje několik modelů strojového učení, které můžete použít na svá data a vzájemně je porovnat, abyste své modely v průběhu času doladili.

