

Na tomto místě se dozvíte:
Přehled vylepšení modelu GPT-4
- Větší kontextová paměť: GPT-4 dokáže zpracovat více textu najednou, což umožňuje lepší porozumění dlouhým konverzacím nebo textům.
- Přesnější odpovědi: GPT-4 poskytuje přesnější a relevantnější odpovědi díky vylepšeným algoritmům a většímu množství tréninkových dat.
- Lepší ztvárnění rolí: GPT-4 je schopnější hrát různé postavy nebo odborníky a udržet konzistentní komunikační styl.
- Zlepšená gramatika a koherence: GPT-4 generuje text s lepší gramatikou a koherencí ve srovnání s předchozími verzemi.
- Vyšší flexibilita: GPT-4 je schopen se lépe přizpůsobit různým úkolům a scénářům, což z něj činí univerzálnější AI nástroj.
- Zvýšená kreativita: GPT-4 je kreativnější, protože byl trénován na různorodých textech, jako je literatura, poezie a hudba.
- Vylepšené vícejazyčné schopnosti: GPT-4 lépe rozumí a generuje přirozený jazyk v několika jazycích.
Hlavní vylepšení modelu GPT-4
GPT-4 má větší kontextovou paměť
Při konverzaci s předchozími verzemi ChatGPT, jako je GPT-3.5, byla jeho schopnost navazovat na dříve zmíněné informace omezena na 4 096 tokenů, což představuje zhruba 8 000 slov nebo více než 4 normostrany textu.
Avšak s GPT-4 se maximální kapacita tokenů zvýšila na 32 768 tokenům, což odpovídá přibližně 64 000 slovům nebo 50 stranám textu. To umožňuje vést mnohem delší konverzace a dokonce udržet souvislosti v rozsáhlých textech, jako jsou novely či povídky, kde si model udrží přehled o ději a postavách od samotného začátku příběhu.
OpenAI v březnu 2023 na své první vývojářské konferenci představilo nejnovější aktualizace svých velkých jazykových modelů (LLM) a nejvýznamnějším zlepšením je uvedení GPT-4 Turbo, který nyní vstupuje do fáze preview. GPT-4 Turbo je aktualizací stávajícího GPT-4 a přináší podstatně rozšířené kontextové okno a přístup k mnohem novějším informacím.
V podstatě to, co GPT-4 Turbo zohledňuje, než vygeneruje jakýkoliv text jako odpověď. K tomu má nyní kontextové okno** o velikosti 128 000 tokenů (jednotka textu nebo kódu, kterou LLM čte), což je podle blogového příspěvku OpenAI ekvivalentní asi 300 stranám textu.
GPT-4 dává přesnější odpovědi
Díky vylepšené architektuře a rozšířenému tréninkovému datasetu je GPT-4 schopno generovat přesnější odpovědi než jeho předchůdce ChatGPT-3.5. Model je vybaven pokročilými mechanismy pro pochopení kontextu otázek a vyhledávání relevantních informací.
GPT-4 je lepší v rozpoznávání nepřesně položených otázek či otázek s chybami, díky čemuž je schopen interpretovat uživatelův záměr a poskytnout relevantní informace. Jeho schopnost rozpoznat a rozlišit faktické informace od názorů nebo spekulací rovněž výrazně zlepšuje kvalitu odpovědí, které poskytuje.
GPT-4 dokáže lépe ztvárnit role
Přehled hlavních vlastností modelu GPT-4
ChatGPT nabízí širokou škálu vlastností a možností, které umožňují efektivní a flexibilní použití jazykového modelu pro různé účely. Některé z nejdůležitějších vlastností a možností zahrnují:
Generování textu: ChatGPT dokáže generovat srozumitelný, relevantní a soudržný text v reakci na zadané dotazy nebo pokyny.
Odpovídání na otázky: Model může zpracovávat a odpovídat na otázky na základě svého tréninkového datasetu a vědomostí získaných z textových dat.
Tvorba obsahu: ChatGPT může být použit k vytváření různých typů obsahu, jako jsou články, blogy, scénáře, básně, nápady na příběhy nebo marketingové texty.
Sumarizace: Model je schopen zpracovat delší texty a poskytnout jejich stručný a srozumitelný souhrn.
Překlady: ChatGPT dokáže překládat text mezi různými jazyky, což může být užitečné pro komunikaci nebo pochopení obsahu v cizím jazyce.
Návrhy a tvorba nápadů: Model může poskytovat návrhy, inspiraci nebo kreativní nápady na základě zadaných témat nebo oblastí zájmu.
Fungování ChatGPT-4
Fungování ChatGPT-4 lze rozdělit do několika klíčových aspektů:
- Strojové učení: ChatGPT je založen na technice strojového učení, což znamená, že se učí z velkého množství textových dat, které mu byly poskytnuty během tréninkového procesu. Tento proces umožňuje modelu pochopit různé jazykové vzory, kontexty a styly.
GPT-4 architektura: ChatGPT využívá architekturu GPT-4, což je evoluce předchozích verzí GPT modelů. GPT-4 je založen na architektuře Transformer, která umožňuje efektivní paralelní zpracování a má schopnost zachytit dlouhodobé závislosti v textu. Díky tomu dokáže ChatGPT lépe porozumět kontextu a generovat kvalitnější odpovědi.
Tokenizace: Před zpracováním dotazů rozdělí ChatGPT text na jednotlivé jednotky zvané tokeny. Tyto tokeny mohou být slova, části slov nebo interpunkční znaménka. Tokenizace umožňuje modelu snadněji zpracovávat text a generovat odpovědi na základě zadaných dotazů.
Attention mechanismus: Jeden z klíčových aspektů architektury Transformer, který využívá ChatGPT, je tzv. attention mechanismus. Tento mechanismus umožňuje modelu zaměřit se na důležité části vstupního textu a zohlednit různé kontexty, což vede k lepšímu porozumění textu a relevantnějším odpovědím.
Generování odpovědí: Po zpracování dotazu generuje ChatGPT odpověď postupným predikováním tokenů, dokud nedosáhne koncového bodu nebo maximálního počtu tokenů. Model se snaží vybrat nejpravděpodobnější token v daném kontextu na základě svého tréninku a vědomostí získaných z textových dat. Tento proces generování odpovědí zahrnuje také rekonstrukci vět a slov do srozumitelného a soudržného textu, který odpovídá uživatelovu dotazu.
- Kontext a prompt engineering: Aby ChatGPT poskytl co nejlepší odpovědi, je důležité správně formulovat dotazy a poskytnout dostatečný kontext. Model může být citlivý na mírné změny ve formulaci otázek, což může ovlivnit jeho odpovědi. Prompt engineering zahrnuje techniky, jak formulovat dotazy tak, aby model poskytl žádoucí výsledky.
Schéma: Proces výcviku modelu strojového učení
Toto schéma popisuje proces trénování modelu strojového učení.
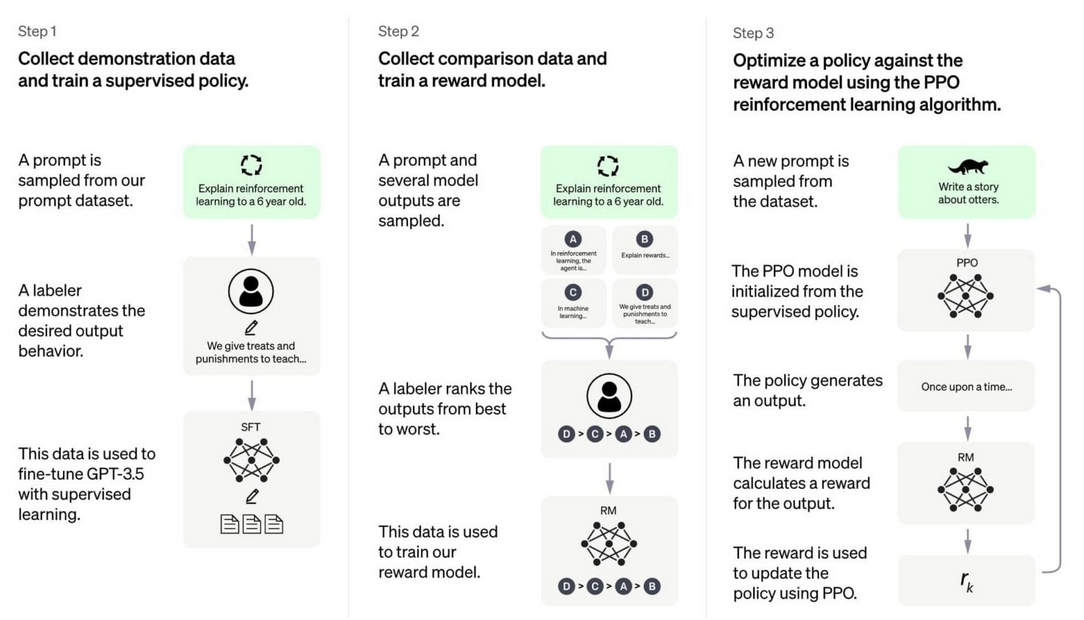
Schema lze vysvětlit takto:
Krok 1: Sběr dat demonstrace a Trénování řízené politiky
- Vybere se příklad (výzva) ze souboru s daty.
- Anotátor (člověk, který označuje data) ukáže požadované výstupní chování modelu.
- Tato data jsou použita k jemnému nastavení modelu GPT-3.5 pomocí metody řízeného učení.
Krok 2: Sběr porovnávacích dat a trénování odměnového modelu
- Vybere se další příklad a několik výstupů modelu.
- Odborník hodnotí výstupy od nejlepšího po nejhorší.
- Tato data se používají k trénování „modelu odměny“, který umožňuje modelu rozlišovat mezi dobrými a špatnými výsledky.
Krok 3: Optimalizace politiky proti „modelu odměny“ pomocí algoritmu posilovacího učení PPO*
- Nový vzorek dotazu je vybrán z databáze.
- Model PPO je inicializován z dohledané politiky.
- Politika generuje výstup.
- Odměnový model spočítá odměnu pro daný výstup.
- Odměna se používá k aktualizaci politiky pomocí PPO.
Proces kombinuje dohledané učení (kdy je model přímo trénován na příkladech správného výstupu) a posilovací učení (kde model se učí z odměn a trestů za své akce) pro zlepšení schopností modelu při generování textu.
Tento popis nezahrnuje specifika jako tokenizace, zpracování dotazů, mechanismus pozornosti (attention mechanism), nebo rekonstrukce textu, které jsou také součástí celkového procesu vytváření odpovědí modelů jako je ChatGPT.
Tyto kroky souvisí s interními mechanismy modelu, kdy **tokenizace rozděluje vstupní text na tokeny, které může model zpracovat, mechanismus pozornosti určuje, na které části vstupu se model má soustředit, a rekonstrukce textu je proces, při kterém model sestavuje odpověď na základě interně vygenerovaných tokenů.
*PPO, což je zkratka pro „Proximal Policy Optimization“ (Proximální optimalizace politiky), je pokročilý algoritmus pro učení s posilováním, který byl vyvinut společností OpenAI. Učení s posilováním je oblast strojového učení, ve které se agent učí provádět akce ve světě tak, aby maximalizoval nějakou formu odměny.
Hlavním cílem PPO je najít nejlepší politiku chování (v tomto kontextu je „politika“ funkce nebo model, který určuje, jaké akce by měl agent vykonat v daném stavu), která maximalizuje celkovou odměnu.
PPO dosahuje tohoto cíle tím, že iterativně upravuje politiku ve směru, který zvyšuje odměny, ale zároveň zavádí mechanismus, který zabraňuje příliš velkým nežádoucím změnám v politice mezi jednotlivými iteracemi. To pomáhá udržet stabilitu učení a zabraňuje problémům, jako je kolaps výkonu, které mohou nastat, když se politika příliš rychle mění.
PPO je široce používán v praxi pro různé aplikace, včetně automatizovaného hraní her, robotiky a jiných oblastí, kde je třeba, aby se modely učily z interakce se složitým prostředím.
**Tokenizace je proces, při kterém se text rozdělí na menší jednotky, které jsou nazývány tokeny. Tyto tokeny mohou být slova, kusy slov, nebo dokonce jednotlivé znaky, v závislosti na tom, jak je tokenizér nastaven.
- Characters: 84, což značí počet znaků v textu.
- Tokens: 20, což ukazuje, že celý text byl rozdělen na 20 tokenů.
Tento proces je základní pro fungování modelů GPT, protože tokeny představují vstupní jednotky, se kterými model pracuje. Každý token může být dále převeden na unikátní ID, které reprezentuje daný token v slovníku modelu. To umožňuje modelu zpracovat text a generovat odpovědi nebo pokračování textu.
Jak funguje GPT–tokenizer?
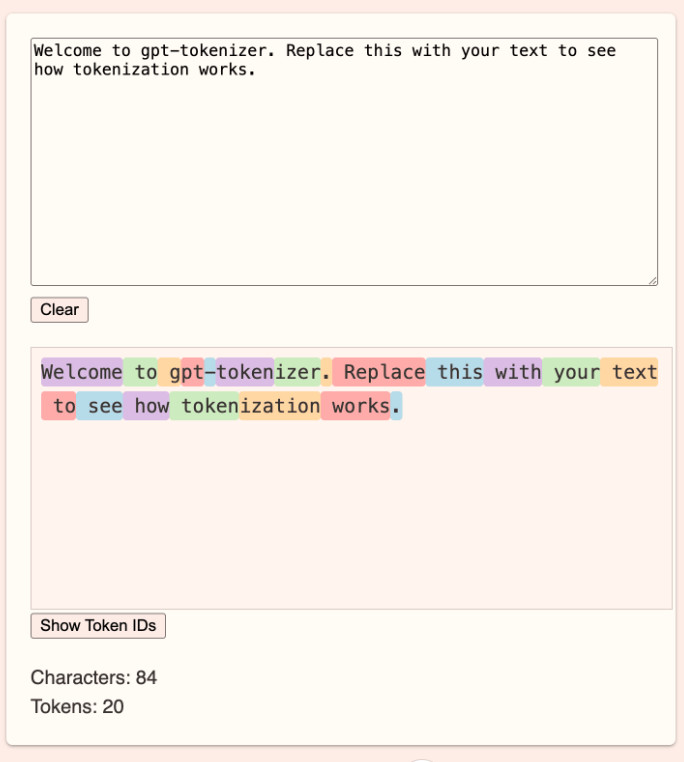
Obrázek demonstruje tokenizaci textu pro modely GPT (Generative Pre-trained Transformer).
***Kontextové okno je množství textu (slova, věty, odstavce), které model může „vidět“ nebo zpracovávat v jednom okamžiku při generování odpovědí nebo pokračování v textu. Kontextové okno určuje, jak daleko dozadu v konverzaci nebo textu může model sahat pro informace, které používá k vytváření koherentní a relevantní odpovědi.
Příklad: Představte si, že čtete knihu a můžete si pamatovat pouze posledních pár stránek, které jste přečetli. To, co si pamatujete (ty poslední stránky), představuje vaše „kontextové okno“. V případě jazykových modelů, jako je GPT-4, je to množství textu, na které se může model odkazovat při odpovídání nebo generování textu.
Velikost kontextového okna je klíčová, protože ovlivňuje schopnost modelu udržovat dlouhodobý kontext v konverzaci nebo textu. Čím větší je kontextové okno, tím více informací může model zapojit do své aktuální odpovědi nebo generovaného textu, což vede k větší koherenci a relevanci.

